
A blog that is a single executable binary
Recently, while browsing lobste.rs, I had the chance to stumble upon this beautiful article, titled: my website is one binary.
It was an idea crazy enough (in a positive way) to try it myself in C.
So, what if I wrote my own blogging “platform” (in the lack of a more suitable term)? But, instead of outputting a static HTML site, my platform outputs a single executable binary file compatible with any *Nix platform. There would be no HTML files, no other assets, just a piece of source code that gets to be recompiled each time I plan to update my “content”. Everything stays in memory, and my site is (an) executable.
To go entirely minimalistic, I’ve decided to impose myself additional rules to follow:
- The software is not going to use any external dependencies other than what the C standard library and whatever the operating system is offering me (POSIX, I am looking at you!);
- I won’t touch CGI; that’s cheating;
- The program will be as concise as possible, and preferably it won’t get bigger than 200-300 lines of code. At the same time, it will be written following a “readable” coding style, without artificially squeezing things on a single line;
- No premature optimization. The software should withstand moderate traffic: a few requests per minute. No need to be extra clever; this is not web-scale;
- I will try to have fun while writing it, even if I have to deal with C strings;
- This prototype won’t replace my current blog, no matter how seductive it may be. I kind of like using ruby, Jekyll, and minimal mistakes;
- No dynamic memory allocation. I will refuse to use
calloc(),malloc(),free()and the likes.
That being (optimistically) settled down, I’ve realized I had to write my own primitive HTTP web server; nothing exceedingly fancy, but something that supports GET requests.
The last time I touched C sockets programming was more than 14 years ago, while I was in UNI. Reading an entire book about the topic was not an option, but I found something better called Beej’s Network Programming guide. If you are already familiar with C, this tutorial has enough information to get you started, and it only takes a few hours to go through it. I’ve copy-pasted the examples, gone through them, modified a few things, and everything worked. End of story.
The next step was to read a bit of the HTTP Protocol. As a backend developer, I have a broad understanding of how it functions. But I was not (recently) put in the position to look closely at what the actual messages look like. I found out that Firefox, the RFC, and the duckduckgo search engine were my friends.
That being said and done, I was good to go.
The code
I’ve unimaginatively named my blogging platform microblog-c. The code and the the samples are available here:
git clone git@github.com:nomemory/microblog-c.git
Running the sample blog
To build the sample blog, we compile microblog.c:
>> gcc -Wall microblog.c -o microblog
>> ./microblog
If everything goes well, the internal server will start serving HTTP requests on port 8080.
If you are curious to see what everything looks like, open a browser: http://localhost:8080, and enjoy:
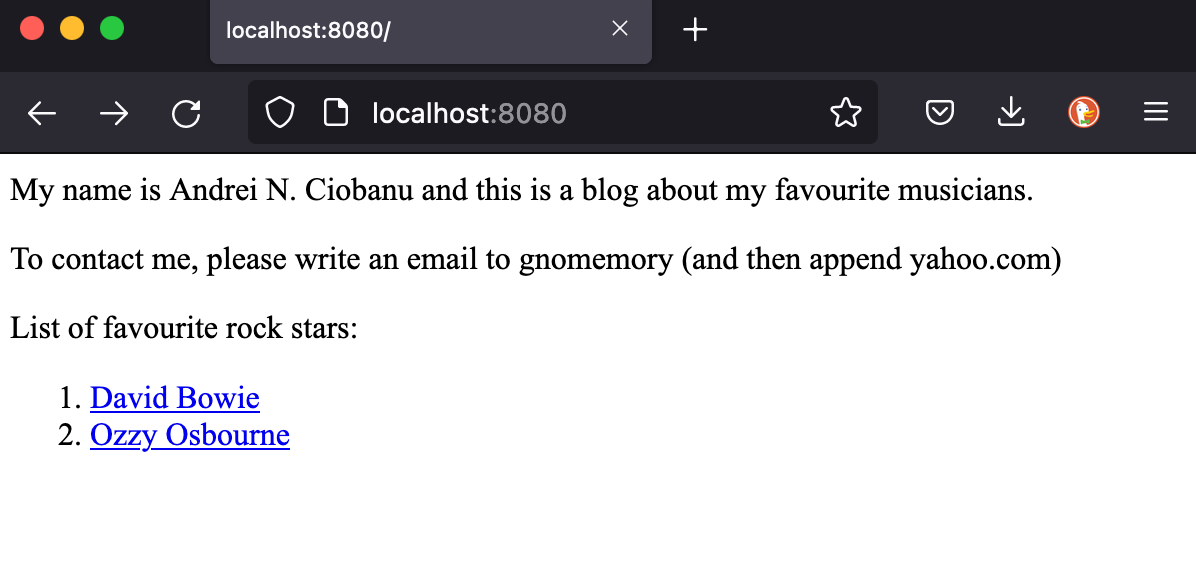


As you can see, CSS is not my strongest skill.
Adding a new blog post to the sample blog
There’s no need to touch the microblog.c source code for adding new content to the blog.
We start by creating a new file in the ./cnt folder called jimihendrix:
{
.content_type = "text/html",
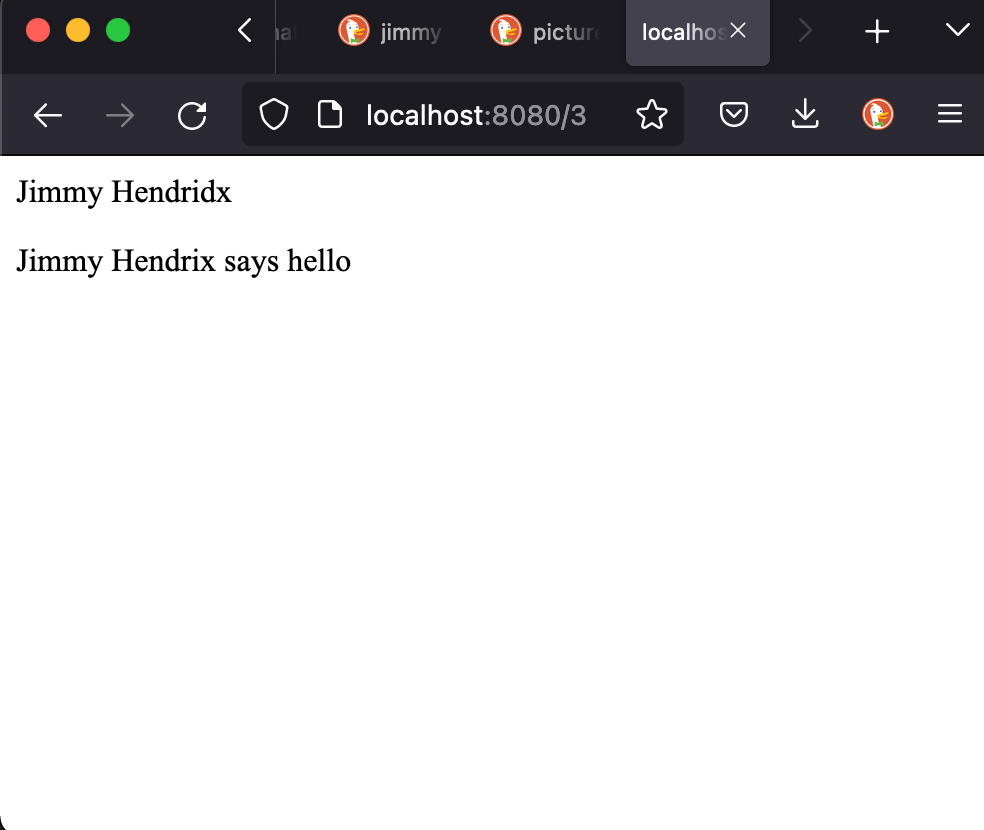
.body = "<p>Jimmy Hendridx</p>"
"<p>Jimmy Hendrix says hello</p>"
}
Note to self: It’s JIMI, not JIMMY!
Then, we reference the new file in the posts file:
#include "cnt/home" /* 0 */
,
#include "cnt/davidbowie" /* 1 */
,
#include "cnt/ozzyosbourne" /* 2 */
,
#include "cnt/jimmyhendrix" /* 3 <---- ADD THIS LINE ---> */
Next, we will make the article visible on the homepage by editing ./cnt/home:
{
.content_type = "text/html",
.body = "<p>My name is Andrei N. Ciobanu and this is a blog about my favourite musicians.<p>"
"<p>To contact me, please write an email to gnomemory (and then append yahoo.com)<p>"
"<p>List of favourite rock stars:<p>"
"<ol>"
"<li><a href='1'>David Bowie</a></li>"
"<li><a href='2'>Ozzy Osbourne</a></li>"
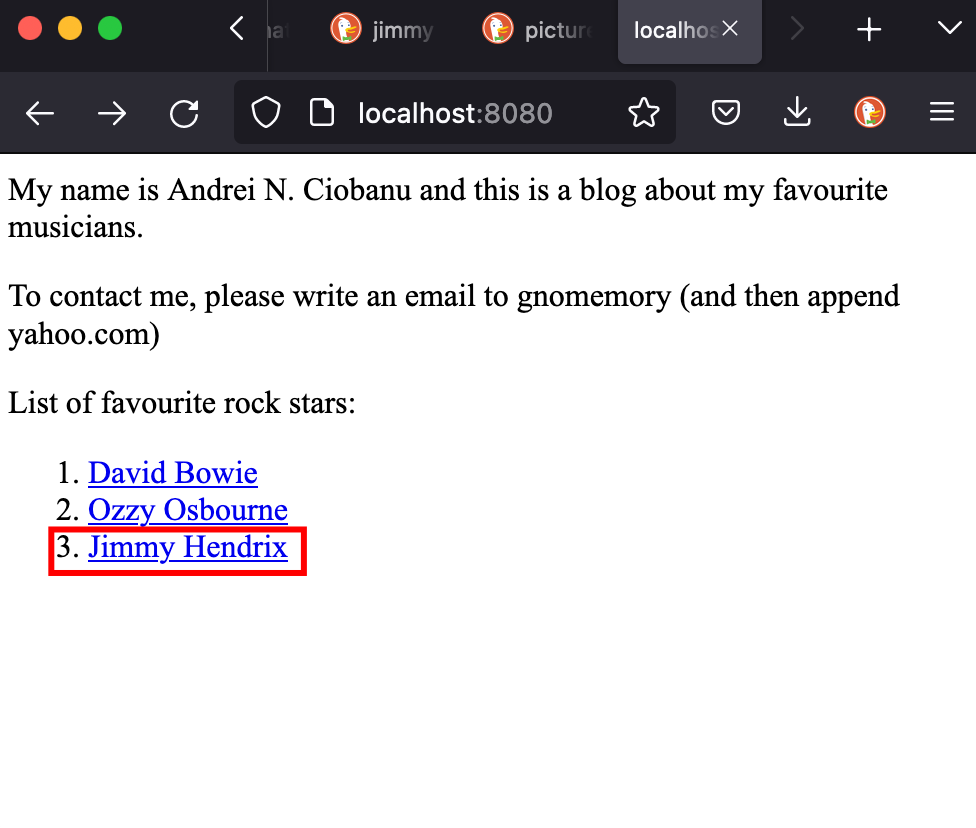
"<li><a href='3'>Jimmy Hendrix</a></li>" /* <<--- HERE*/
"</ol>"
}
And the final step is to re-compile the blog and re-run the server:
>> gcc -Wall microblog.c -o microblog
>> ./microblog
If we open http://localhost:8080 again we will the changes:
How everything works
The following part of the article is not a step-by-step guide, so I suggest opening microblog.c to follow the code as you continue reading.
The model and a neat pre-processor trick
We start by defining our model, struct post_s:
#define TEXT_PLAIN "text/plain"
#define TEXT_HTML "text/html"
typedef struct post_s
{
char *content_type;
char *body;
} post;
We will keep things simple from the beginning: a blog post has a content_type and a body. The content_type can be either:
text/htmlif we plan to server classical HTML content;text/plainif we want to work with.txtfiles.
Our main strategy is to keep all the blog posts inside a global array of post posts[] which is known at compile-time:
#include <stdio.h>
#define TEXT_PLAIN "text/plain"
#define TEXT_HTML "text/html"
typedef struct post_s
{
char *content_type;
char *body;
} post;
post posts[] = {
{
.content_type = TEXT_PLAIN,
.body = "Article 0"
},
{
.content_type = TEXT_HTML,
.body = "<p>Article 1</p>"
}
};
const size_t posts_size = (sizeof(posts) / sizeof(post));
int main(void) {
// Printing the posts to stdout
for(size_t i = 0; i < posts_size; i++) {
printf("post[%zu].content_type = %s\n", i, posts[i].content_type);
printf("post[%zu].body =\n %s\n", i, posts[i].body);
printf("\n");
}
return 0;
}
The posts array contains all the content of our blog. Each article is accessible by its index in the global array.
To modify or add something, we would have to alter the source code and then re-compile. But what if there is a way to keep the content outside the source file?
Remember the #include pre-processor directive ? Well, contrary to popular belief, its usage it’s not limited to header files. We can actually use it to “externalize” our content, and #include it just before compilation:
/* microblog.c */
post posts[] = {
#include "posts"
};
Where ./posts is a file on the disk with the following structure:
/* posts file */
{
.content_type = TEXT_PLAIN,
.body = "Article 0"
},
{
.content_type = TEXT_HTML,
.body = "<p>Article 1</p>"
}
When we #include it, all of it gets inserted back into the source code.
At this point, we can go even further and separate the articles in their own files and further include them in ./posts. To easily visualise what’s happening check out the following diagram:

The server
To serve our blog content to browsers, we will have to implement a straightforward HTTP Server that supports only the GET request.
A typical GET request looks like this:
GET /1 ........
...............
...............
...............
...........\r\n
The request is a char* (string) that ends with \r\n (CRLF), and starts with GET /<resource>.
Of course, the spec is infinitely more complex than this. But for the sake of simplicity, we will concentrate only on the first line, ignoring everything else. We will accept only numerical paths (<resources>). Internally those paths represent indices in our post posts[] array. By convention, our homepage will be posts[0].
For example, to GET the homepage of our blog, the request should like:
GET / .........
...............
...............
...............
...........\r\n
To GET another post, let’s say the article posts[2], the request should look like this:
GET /2 ........
...............
...............
...............
...........\r\n
The code for creating the actual server is quite straightforward if you are already familiar with C socket programming (I wasn’t, so the code is probably not the best):
#define DEFAULT_BACKLOG 1000
#define DEFAULT_PORT 8080
#define DEFAULT_MAX_FORKS 5
#define DEFAULT_TIMEOUT 10000
int max_forks = DEFAULT_MAX_FORKS;
int cur_forks = 0;
void start_server() {
// Creates a Server Socket
int server_sock_fd = socket(
AF_INET, // Address Familiy specific to IPV4 addresses
SOCK_STREAM, // TCP
0
);
if (!server_sock_fd)
exit_with_error(ERR_SOC_CREATE);
struct sockaddr_in addr_in = {.sin_family = AF_INET,
.sin_addr.s_addr = INADDR_ANY,
.sin_port = htons(DEFAULT_PORT)};
memset(addr_in.sin_zero, '\0', sizeof(addr_in.sin_zero));
// Bind the socket to the address and port
if (bind(server_sock_fd, (struct sockaddr *)&addr_in,
sizeof(struct sockaddr)) == -1)
exit_with_error(ERR_SOC_BIND);
// Start listening for incoming connections
if (listen(server_sock_fd, DEFAULT_BACKLOG) < 0)
exit_with_error(ERR_SOC_LISTEN);
int client_sock_fd;
int addr_in_len = sizeof(addr_in);
for (;;) {
// A cliet has made a request
client_sock_fd = accept(server_sock_fd, (struct sockaddr *)&addr_in,
(socklen_t *)&addr_in_len);
if (client_sock_fd == -1) {
// TODO: LOG ERROR BUT DON 'T EXIT
exit_with_error(ERR_SOC_ACCEPT);
}
pid_t proc = fork();
if (proc < 0) {
// log error
// Close client
close(client_sock_fd);
} else if (proc == 0) {
// We serve the request on a different
// subprocess
server_proc_req(client_sock_fd);
} else {
// We keep track of the number of forks
// the parent is creating
cur_forks++;
// No reason to keep this open in the parent
// We close it
close(client_sock_fd);
}
// Clean up some finished sub-processes
if (!(cur_forks<max_forks)) {
while (waitpid(-1, NULL, WNOHANG) > 0) {
cur_forks--;
}
}
}
close(server_sock_fd);
}
We start by creating server_sock_fd, which binds and listens to DEFAULT_PORT=8080. If those operations fail, the code exits and returns either ERR_SOC_BIND or ERR_SOC_LISTEN, depending on the error.
The DEFAULT_BACKLOG refers to the max length of the (internal) queue of pending socket connections server_sock_fd can grow to. If a connection request arrives when the (internal) queue has more elements than DEFAULT_BACKLOG , the client may receive an error indicating ECONNREFUSED.
If the first step is successful, we enter an infinite loop in which we accept new connections. Then, we process each incoming request in its subprocess (using fork()).
There’s a max limit on the number of parallel forks we can have (see max_forks). Our code keeps track of the running number of forks through cur_forks. Whenever cur_forks is close to the limit, we start reaping the zombie sub-processes using waitpid(...).
The function responsible with processing the request (server_proc_req) looks like this:
#define REQ_SIZE (1 << 13)
#define REQ_RES_SIZE (1 << 4)
#define REP_MAX_SIZE (REP_H_FMT_LEN + REP_MAX_CNT_SIZE)
void server_proc_req(int client_sock_fd) {
char rep_buff[REP_MAX_SIZE] = {0};
char req_buff[REQ_SIZE] = {0};
char http_req_res_buff[REQ_RES_SIZE] = {0};
int rec_status = server_receive(client_sock_fd, req_buff);
int rep_status;
if (rec_status == SR_CON_CLOSE) {
// Connecon closed by peer
// There 's no reason to send anything further
exit(EXIT_SUCCESS);
} else if (rec_status == SR_READ_ERR || rec_status == SR_READ_OVERFLOW) {
// Cannot Read Request(SR_READ_ERR) OR
// Request is bigger than(REQ_SIZE)
// In this case we return 400(BAD REQUEST)
rep_status = set_http_rep_400(rep_buff);
} else if (http_req_is_get(req_buff)) {
// Request is a valid GET
if (http_req_is_home(req_buff)) {
// The resource is "/" we return posts[0]
rep_status = set_http_rep_200(posts[0].content_type, posts[0].body,
strlen(posts[0].body) + 1, rep_buff);
} else {
// The resource is different than "/"
size_t p_idx;
set_http_req_res(req_buff, 5, http_req_res_buff);
if (set_post_idx(&p_idx, http_req_res_buff) < 0) {
// If the resource is not a number, or is a number
// out of range we return 404 NOT FOUND
rep_status = set_http_rep_404(rep_buff);
} else {
// We return the corresponding post based on the index
struct post_s post = posts[p_idx];
rep_status = set_http_rep_200(post.content_type, post.body,
strlen(post.body) + 1, rep_buff);
}
}
} else {
// The request looks valid but it 's not a get
// We return 501
rep_status = set_http_rep_501(rep_buff);
}
if (rep_status < 0) {
// There was an error constructing the response
// TODO LOG
} else {
server_send(client_sock_fd, rep_buff);
}
close(client_sock_fd);
exit(EXIT_SUCCESS);
}
We define three buffers:
rep_buff- Here is where we keep the response we are sending back to the client;req_buff- This contains the request coming from the client;http_req_res_buff- Here we keep the resource (postsindex) we want to access. This is something we extract fromreq_buff.
The most important functions called from server_proc_req are server_receive and server_send. These two methods read and write data to/from the socket.
The code is quite straight-forward:
enum server_receive_ret {
SR_CON_CLOSE = -1,
SR_READ_ERR = -2,
SR_READ_OVERFLOW = -3
};
static int server_receive(int client_sock_fd, char *req_buff) {
int b_req = 0;
int tot_b_req = 0;
while ((b_req = recv(client_sock_fd, &req_buff[tot_b_req],
REQ_SIZE - tot_b_req, 0)) > 0) {
/* Connection was closed by the peer */
if (b_req == 0) return SR_CON_CLOSE;
/* Reading Error */
if (b_req == -1) return SR_READ_ERR;
tot_b_req += b_req;
/* HTTP Requst is sent */
if (http_req_is_final(req_buff, tot_b_req)) break;
/* req_buff overflows */
if (tot_b_req >= REQ_SIZE) return SR_READ_OVERFLOW;
}
return tot_b_req;
}
enum server_send_errno { SS_ERROR = -1 };
static int server_send(int client_sock_fd, char *rep_buff) {
int w_rep = 0;
int tot_w_rep = 0;
size_t total = strlen(rep_buff) + 1;
while ((w_rep = send(client_sock_fd, rep_buff, total - tot_w_rep, 0)) > 0) {
if (w_rep < 0) return SS_ERROR;
tot_w_rep += w_rep;
}
return tot_w_rep;
}
The two methods (server_receive and server_send) are actual wrappers over send() and recv() that add additional checks on-top.
For example, in server_receive we make sure we read bytes (b_req) up until we encounter CRLF (http_req_is_final) or we overflow (we read more bytes than req_buff can hold).
In server_send we make sure that we send all the bytes from rep_buff. Calling send once doesn’t guarantee that; that’s why we do everything in a loop that checks how manys bytes we’ve sent (using w_rep).
Lastly, the methods: set_http_rep_200, set_http_rep_404, set_http_rep_500 are all “overloaded” (if we can call them like this) for the set_http_rep_ret method:
#define REP_FMT "%s%s\n"
#define REP_H_FMT "HTTP/%s %d \nContent-Type: %s\nContent-Length: %zu\n\n"
#define REP_H_FMT_LEN (strlen(REP_H_FMT) + 1 + (1 << 6))
#define REP_MAX_CNT_SIZE (1 << 19)
#define REP_MAX_SIZE (REP_H_FMT_LEN + REP_MAX_CNT_SIZE)
enum set_http_rep_ret {
SHR_ENC_ERROR = -1,
SHR_HEAD_OVERFLOW = -2,
SHR_CNT_ENC_EROR = -3,
SHR_CNT_OVERFLOW = -4
};
static int set_http_rep(const char *http_ver, const http_s_code s_code,
const char *cnt_type, const char *cnt,
const size_t cnt_size, char *rep_buff) {
char h_buff[REP_H_FMT_LEN] = {0};
int bw_head = snprintf(h_buff, REP_H_FMT_LEN, REP_H_FMT, http_ver, s_code,
cnt_type, cnt_size);
if (bw_head < 0)
return SHR_ENC_ERROR;
else if (bw_head >= REP_H_FMT_LEN)
return SHR_HEAD_OVERFLOW;
size_t buff_size = bw_head + cnt_size;
if (buff_size > REP_MAX_SIZE) return SHR_CNT_OVERFLOW;
int bw_rep = snprintf(rep_buff, buff_size, REP_FMT, h_buff, cnt);
if (bw_rep < 0) return SHR_CNT_ENC_EROR;
return bw_rep;
}
This method constructs the message we will send back to the browser and makes sure we don’t overflow. It starts by building the header response:
"HTTP/%s %d \nContent-Type: %s\nContent-Length: %zu\n\n"
And then adding the actual content:
#define REP_FMT "%s%s\n"
I’ve used snprintf() for both string concatenations to check for possible overflows or encoding errors.
That’s all.
Conclusions
All in all, microblog.c was an exciting experiment. The code is to be taken lightly: like a combination of software minimalism, poorly written C (waiting for feedback, actually), and a late April’s Fools Day joke.
Comments